주제: 랜덤 포레스트
쓰다: 2023-03-04실행: ① 파이썬: 3.9.13 ② 판다: 1차 4차 4차 ③ sklearn : 1. 1. 1
데이터: Pima 인디언 당뇨병 데이터베이스
앙상블 학습 방법 투표, 배깅, 부스팅 및 스태킹과 같은 방법이 있습니다. 이 중 Voting과 Bagging은 여러 분류법을 통해 투표하고 최종 예측 결과를 결정하는 방법입니다. 하지만, 투표는 서로 다른 알고리즘으로 각 분류기에서 결합됩니다.하지만, 배깅은 다른 데이터 샘플을 취하고 동일한 분류기 알고리즘을 사용합니다.그것은 학습의 방법입니다
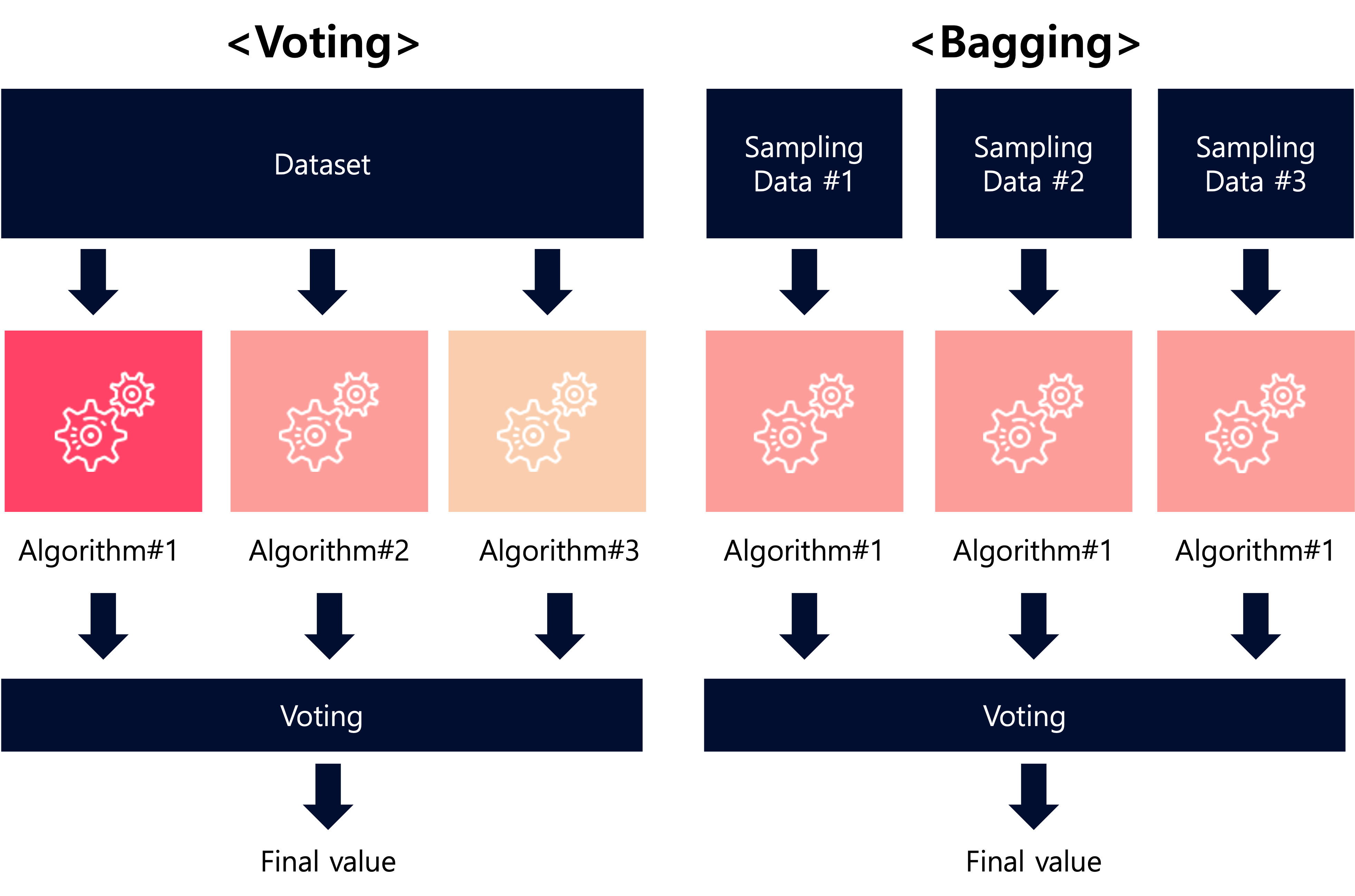
후자의 배깅 방식에서 사용되는 대표적인 알고리즘은 Random Forest이다. 이번 포스팅에서는 랜덤포레스트 사용법에 대해 공유해 보도록 하겠습니다.
하나. 데이터 준비
사용된 데이터는 의사결정나무 알고리즘에 적용된 데이터와 동일하였다. 동일한 데이터에 의사결정나무 알고리즘을 적용하는 방법이 필요하다면 이전 글을 읽어보시기 바랍니다.
- 03/03/2023 – ( 데이터 과학/데이터 과학) – (기계 학습) 결정 트리 실습 – Pima Indians Diabetes Database
Pima 인디언 당뇨병 데이터베이스
https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database?resource=download
Pima 인디언 당뇨병 데이터베이스
진단적 측정을 기반으로 당뇨병 발병 예측
www.kaggle.com
2. 샘플 애플리케이션
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# Read the dataset
df= pd.read_csv('./diabetes.csv')
# Apply randomforestclassifier model without setting the parameters
rf_clf = RandomForestClassifier(random_state = 70)
# Training the model with the dataset
X_train,X_test, y_train, y_test = train_test_split(df.iloc(:,:-1), df.iloc(:,-1),
test_size =0.3, random_state =77)
rf_clf.fit(X_train, y_train)
# Predect and calculate the accuracy
pred = rf_clf.predict(X_test)
accu = accuracy_score(y_test, pred)
print("랜덤포레스트 예측정화도:{0:.4f}".format(accu)) # 결과값 : 0.7532결정트리의 예측정화도: 0.6797랜덤포레스트 예측정화도:0.7532
삼. 성능 향상
3.1. 최적의 성능 매개변수 찾기
from sklearn.model_selection import GridSearchCV
parmas={'n_estimators' : (100, 200),
'max_depth' : (6, 8, 10, 12),
'min_samples_leaf': (8,12,18,20),
'min_samples_split' : (8, 16, 25)
}
grid_cv= GridSearchCV(rf_clf,
param_grid = parmas,
cv=2, n_jobs=-1
)
grid_cv.fit(X_train, y_train)
print("Gridsearchcv 최고 평균 정확도 수치 : {0:.4f}".format(grid_cv.best_score_))
print("Gridsearchcv 최적 하이퍼 파라미터:", grid_cv.best_params_)n_job = -1이면 모든 CPU 코어를 학습에 사용할 수 있습니다.
3.2 사용
rf_clf2 = RandomForestClassifier(n_estimators=200, max_depth = 8,
min_samples_leaf=12, min_samples_split=8)
rf_clf2.fit(X_train, y_train)
pred = rf_clf2.predict(X_test)
print('{0:.4f}'.format(accuracy_score(y_test, pred)))
유효한 매개변수는 다음과 같습니다.
- ‘부트스트랩’
- ‘ccp_알파’
- ‘class_weight’
- ‘기준’
- ‘최대 깊이’
- ‘max_features’
- ‘max_leaf_nodes’
- ‘최대 샘플’
- ‘최소_불순물_감소’
- ‘min_samples_leaf’
- ‘min_samples_split’
- ‘min_weight_fraction_leaf’,
- ‘n_estimators’
- ‘n_jobs’
- ‘oob_score’
- ‘random_state’
- ‘상세한’
- ‘웜부츠’
참조
- sklearn.ensemble.RandomForestClassifier 속성: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
- (서적) 「파이썬 머신러닝 완전 가이드」 4장
- graphviz 설치 오류: https://wscode.70
- Sayitkillen의 기계 학습: https://wscode.68
(머신러닝) scikit-learn으로 시작하는 머신러닝
주제: Scikit-Learn의 기계 학습 생성일: 2023-02-04 버전: pandas 1.4.4 / sklearn 1.1.1 사용된 데이터: Iris 데이터(sklearn.datasets import load_iris에서) 안녕하세요, Lucas입니다. 오늘날 Python을 사용한 머신 러닝
wscode.tistory.com
sklearn.ensemble.RandomForestClassifier
sklearn.ensemble.RandomForestClassifier를 사용하는 예: scikit-learn 0.24 릴리스 하이라이트 scikit-learn 0.24 릴리스 하이라이트 scikit-learn 0.22 릴리스 하이라이트…
scikit-learn.org